摘要:本文详细介绍了如何基于 CMDB(Configuration Management Database)实现全链路故障排查拓扑的构建与应用,并探讨了 CMDB 在未来智能化发展中的潜力。文章适用于运维工程师、值班故障处理人员,以及 CMDB 配置经理和管理员。
涉及关键词: CMDB 治理,故障排查拓扑, CMDB 自动采集技术、AI在 CMDB 的应用
01.引言:为什么 CMDB 的全链路拓扑建设如此重要?
在现代 IT 运维管理中,复杂的系统架构和多样化的应用场景使得故障排查变得极具挑战性。对于运维工程师、值班故障处理人员,以及 CMDB 配置经理和管理员来说,快速、准确地定位故障根因是保障业务连续性和用户体验的关键。然而,随着 IT 基础设施的日益复杂,单纯依赖传统的监控和管理工具已无法满足当代运维要求。1)什么是 CMDB ?
CMDB(Configuration Management Database)是一种用于存储 IT 基础架构中所有配置项(CI)及其关系的数据仓库。在 CMDB 中,每个 CI 都可以是一个实体(例如服务器、交换机、安全设备等),或者是一个逻辑资源(例如虚拟机、应用服务、存储卷等)。CMDB 的作用不仅在于收集和管理这些 CI 的状态信息,更重要的是了解和记录它们之间的相互关系,以及这些关系在业务系统中的位置和作用。
2)全链路故障排查拓扑的意义
构建一个全面、健壮的全链路故障排查拓扑,对于提升 IT 运维效率至关重要。通过完善的拓扑结构,我们能够:
- 快速响应与定位故障:通过直观的拓扑图可以快速定位故障点,节省排查时间。
- 全面掌控关键资源:全面了解不同资源,包括前端负载均衡、应用、主机、云平台、物理服务器、安全设备(如防火墙、IPS、IDS)和存储系统之间的依赖关系,确保各个环节互动良好。
- 提升运维自动化水平:实现对资源依赖关系的自动化管理,减少人工干预,提高运维效率和准确性。
- 降低业务中断风险:通过预防性维护和及时故障处理,降低业务系统的停机时间和用户受到影响的风险。
通过本文的介绍,运维人员、配置经理和管理员将能够更好地理解和使用 CMDB 全链路拓扑,提升 IT 服务管理水平,实现业务稳定性和持续性保障,本文具体内容下:
- 拓扑建设思路:从整体规划到逐层细化,结合业务需求设计全链路拓扑结构。
- CI 模型的建立:定义各类 CI 的属性和字段,以最小化原则精简设计,确保重要信息的全面覆盖。
- CI 关系的建立:设置关键资源之间的依赖关系,确保拓扑图的准确性和可读性。
- CI 属性和关系的采集:介绍数据采集的技巧与工具,重点阐述关系采集的方法与技术。
- 故障排查的应用示例:通过具体案例演示如何利用拓扑定位和解决实际运维中的故障,提升运维效率。
02.拓扑建设思路
在构建完善的 CMDB 全链路故障排查拓扑的过程中,需遵循一定的建设思路,以确保拓扑结构科学合理、数据准确全面,并具备动态更新的能力。本文将重点介绍拓扑建设的统一入口视角、自顶向下与自底向上结合的建设方式,以及构建过程中的设计准则。
1)统一入口视角:以业务为中心
拓扑建设的首要思路是以业务为中心展开。业务需求是系统运维的核心,从业务视角出发,可以更直观地体现各个 IT 资源对业务运行的支持程度。
- 业务需求分解:从企业的关键业务出发,逐层分解与其相关的各类 IT 资源。这些资源可能包括了前端的负载均衡设备、应用服务、运行应用的主机、底层的云平台和物理服务器、网络设备(如防火墙、IPS/IDS等),以及存储系统。
- 关联关系分析:把每一个业务需求逐一分析,确定支撑这些需求的设备和资源之间的直接与间接关系。例如,某一关键业务应用可能依赖于多个数据库,而这些数据库又分别运行在不同的虚拟机和物理服务器上。
通过这样的方式,我们能够构建出一幅详尽的业务资源依赖关系图。这张图不仅展示了关键业务的组成和运作机制,也能帮助我们在故障发生时,快速确认业务所依赖的具体资源以及它们之间的关联关系。
2)自顶向下与自底向上结合的建设方式
在具体操作中,可以采用自顶向下与自底向上相结合的方式进行拓扑建设。
- 自顶向下(Top-down):从业务流程和系统架构图入手,确定各个业务需求所涉及的关键节点和依赖关系。逐层细化:从高层业务逻辑到中层服务组件,最终细化到底层的基础设施设备(如服务器、网络设备等)。
- 自底向上(Bottom-up):从物理和逻辑基础架构出发,逐步识别和采集各个具体配置项(CI)的信息。汇总形成各个资源节点的属性和状态数据,建立这些节点之间的依赖和互动关系。
结合方式:
- 统筹关联:通过自顶向下的方法构建出大框架,再结合自底向上的数据采集,确保每个环节和节点都得到了覆盖和连接。
- 双向验证:顶层设计提供了一个总体规划,而底层数据的采集和反馈,则确保了设计的合理性与实用性。两者彼此验证,确保拓扑结构的完整性和准确性。
3)构建拓扑时的设计准则
在拓扑建设过程中,需遵循以下设计准则,确保拓扑结构的高效性和易用性:
- 数据完整性:确保拓扑结构覆盖所有关键节点和关系。避免遗漏重要的组件和联接。方法:定期审查和更新 CMDB 中的 CI,保证数据的实时性和准确性。
- 数据最小化:只采集并管理必要的字段,避免数据冗余和信息泛滥。方法:制定采集策略,初期只采集关键字段,确保每个字段都有明确用途。逐步优化字段模型。
- 动态更新能力:保证拓扑数据与实际状态保持同步,适应环境动态变化。方法:通过自动化脚本和智能化工具,实现对 CI 及其关系的实时监测和更新。
- 易读性与可视化:构建清晰易读的拓扑图,辅助可视化工具帮助快速理解和运维。方法:采用专业的可视化工具,将复杂的关系以图形化形式呈现,增强直观感。
- 安全与合规:在数据采集和展示过程中,依照企业的安全和合规要求,保护敏感信息。方法:制定并实施数据治理和安全策略,防止数据泄露和误用。
通过以上准则的指导,我们能够构建出一个既全面详细,又高效实用的 CMDB 全链路故障排查拓扑,为运维管理和故障排查提供坚实保障。在接下来的章节中,我们将细化这些步骤,详细讲解 CI 模型的建立、关系的确立、属性和关系的采集方法,并结合实际案例进行应用示范。
03.CI 模型的建立
CMDB 的核心在于将 IT 环境中所有的设备、系统和虚拟资源抽象成配置项(Configuration Item,简称 CI),并在此基础上进行统一管理。CI 模型的建立是构建 CMDB 的第一步,关系到数据的规范、拓扑的结构化,以及后续故障排查的效率。在这一部分,我们将详细说明 CI 是什么,如何遵循最小化原则设计精简高效的数据模型,并通过典型场景示例展示关键 CI 的设计模板。
1)什么是 Configuration Item(CI)
配置项(CI) 是 CMDB 中的最基本构成单元,代表 IT 系统中的实体或逻辑对象。CI 不仅包含资源的自身属性,还与其他 CI 建立关联,形成全链路的模型。因此,一个优秀的 CI 一定要具备以下两个特点:
- 独立性:作为一个独立对象,CI 能够被单独管理或操作。例如,一台服务器,一个负载均衡设备,或者一个存储卷。
- 关联性:CI 并非孤立存在,而是与其他 CI 形成复杂的依赖或支持关系。例如,应用服务依赖于主机,主机运行在虚拟机上,而虚拟机可能托管在某个云平台上。
通过准确地建模 CI,我们可以清晰呈现 IT 系统中设备和资源的具体角色,并为全链路拓扑的建立奠定基础。
2)CI 模型设计的最小化原则
在构建 CI 模型时,需遵循“最小化原则”,即只记录必要的字段和属性,确保数据的简洁性和高效性。过于复杂或冗余的模型不仅会增加维护成本,还可能导致 CMDB 系统性能下降,降低实用性。
(1)最小化原则的具体方法:
- 识别关键字段:基于系统管理和故障排查需求,设计出对目标明确、对故障定位至关重要的字段。例如,一个主机的核心字段包括主机名、IP 地址、CPU 配置等,而背景颜色或外壳材料这类无关字段可以剔除。
- 避免不必要的冗余:相同的信息不要重复存储,尽量通过关系模型来引用。例如,不需要在每个应用服务的 CI 中重复存储主机信息,而是通过主机与应用服务的关联关系动态获取。
(2)字段设计的示例:
以下是符合最小化原则的字段设计模板:
1. 主机:
- 必要字段:主机名、IP 地址、操作系统、CPU 核数、内存大小。
- 非必要字段(剔除):生产日期、物理尺寸。
2. 网络设备(如交换机、防火墙):
- 必要字段:设备名、IP、端口数、厂商。
- 非必要字段(剔除):外壳颜色、销售代理。
通过科学定义字段,我们能够减少不必要的数据冗余,同时确保故障定位所需的关键信息持续可用。
3)典型场景的CI模型模板
在 IT 系统中,不同类型的资源和设备对应不同的 CI 模型。以下是针对常见场景的几个模板设计:
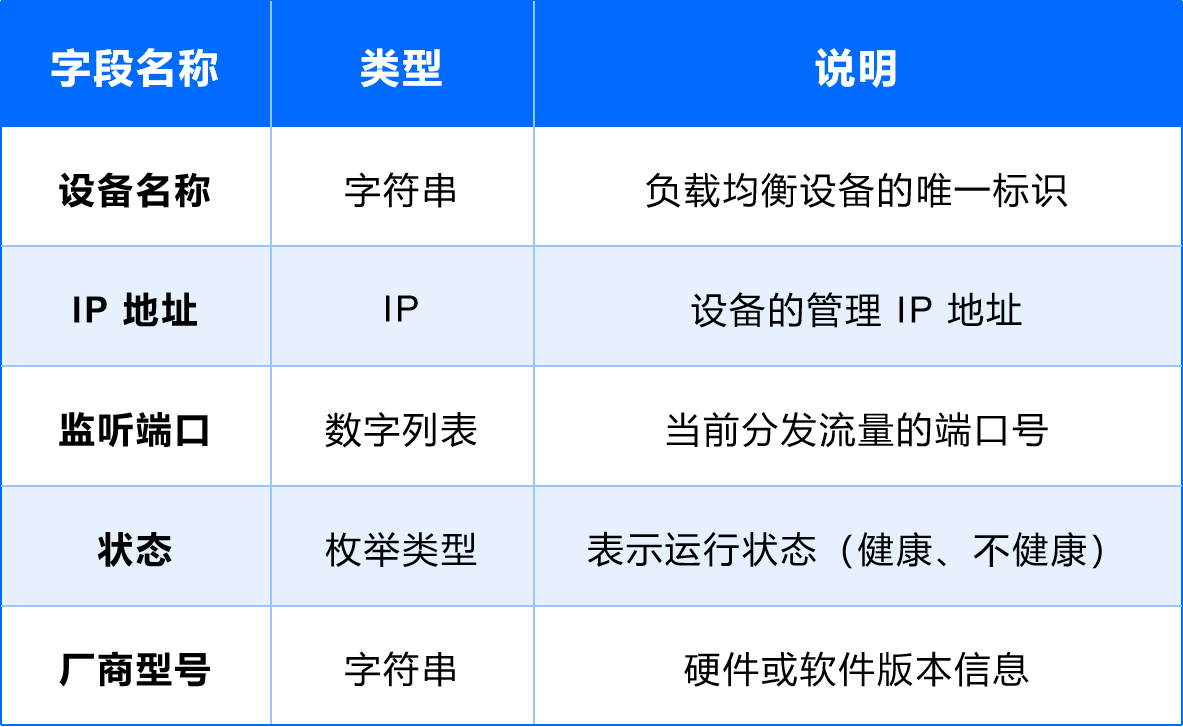
(1)负载均衡设备
用途:负责分发前端业务流量。
字段设计:
(2)应用服务
用途:分发业务逻辑并处理用户请求。
字段设计:

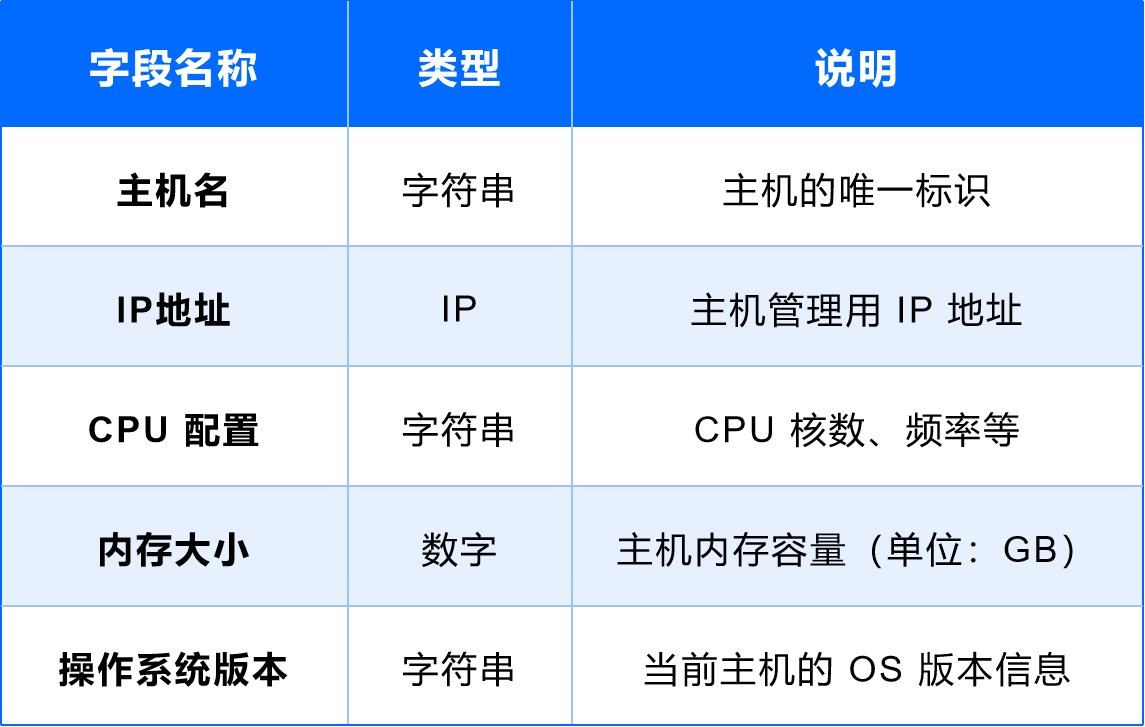
(3)主机
用途:承载基础软件及应用运行。
字段设计:
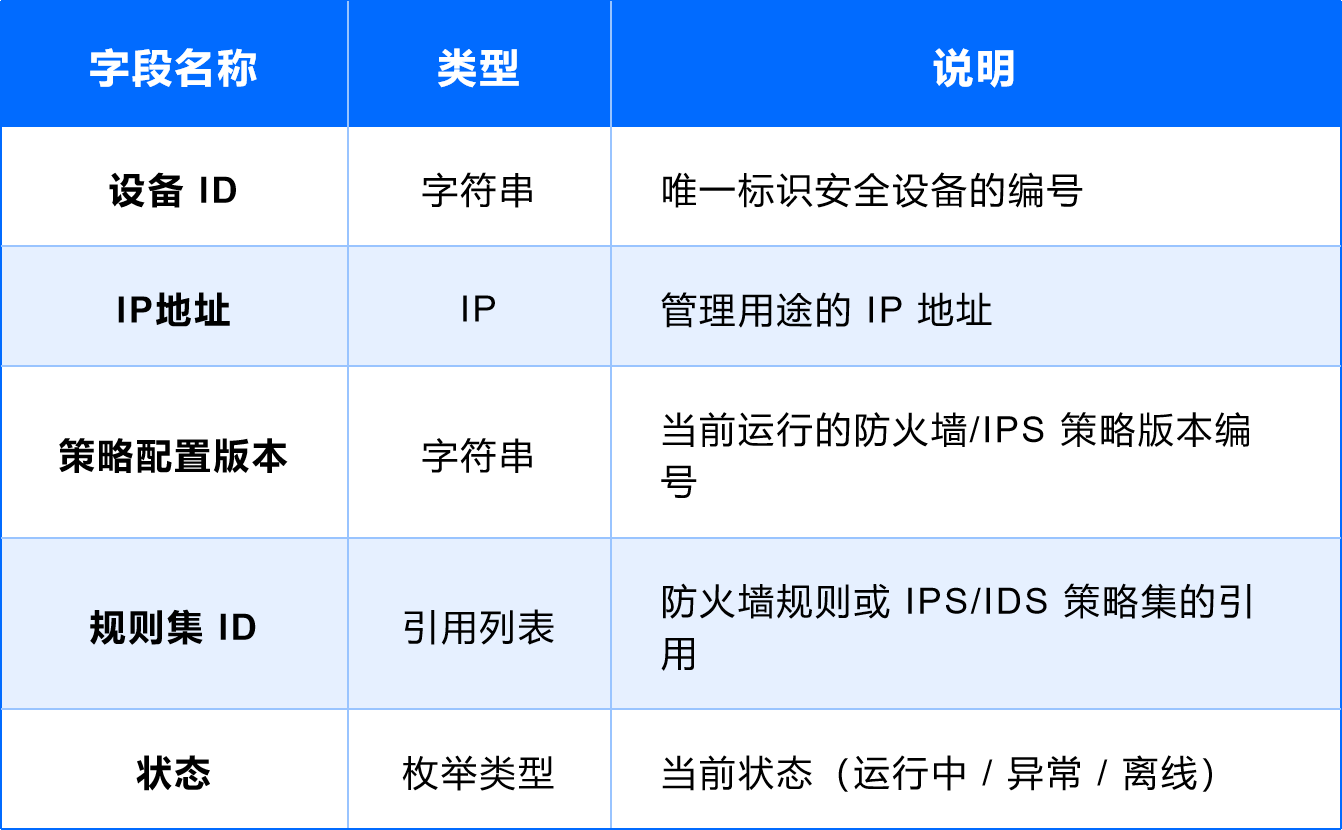
(4)防火墙 / IPS / IDS 等安全设备
用途:保护系统安全,检测和防御攻击。
字段设计:
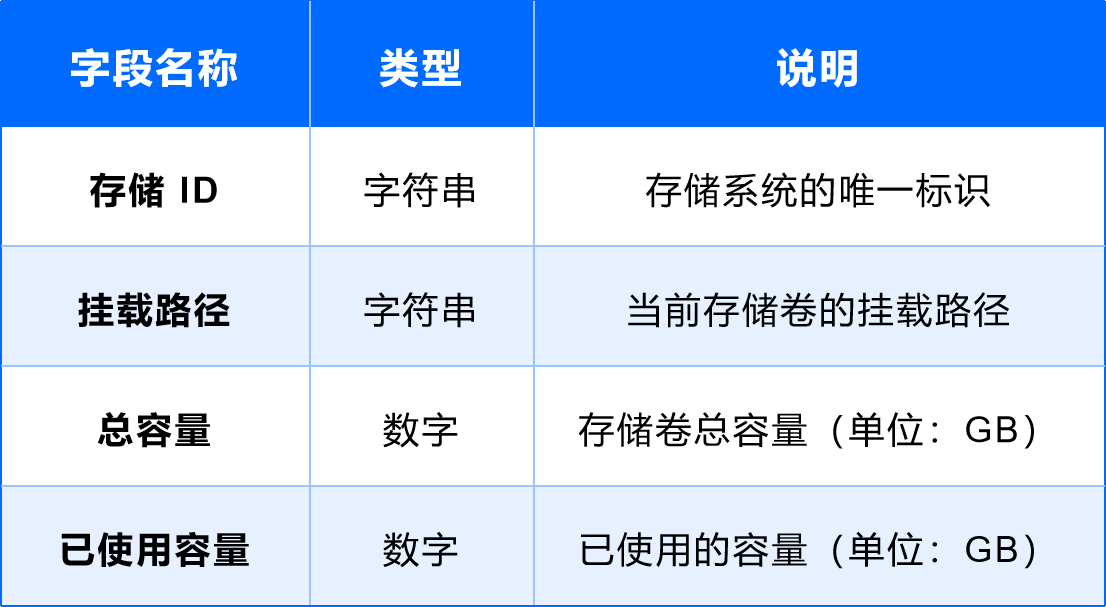
(5)存储系统
用途:提供数据存储服务。
字段设计:
(6)交换机
用途:提供网络连接和数据包转发。
字段设计:
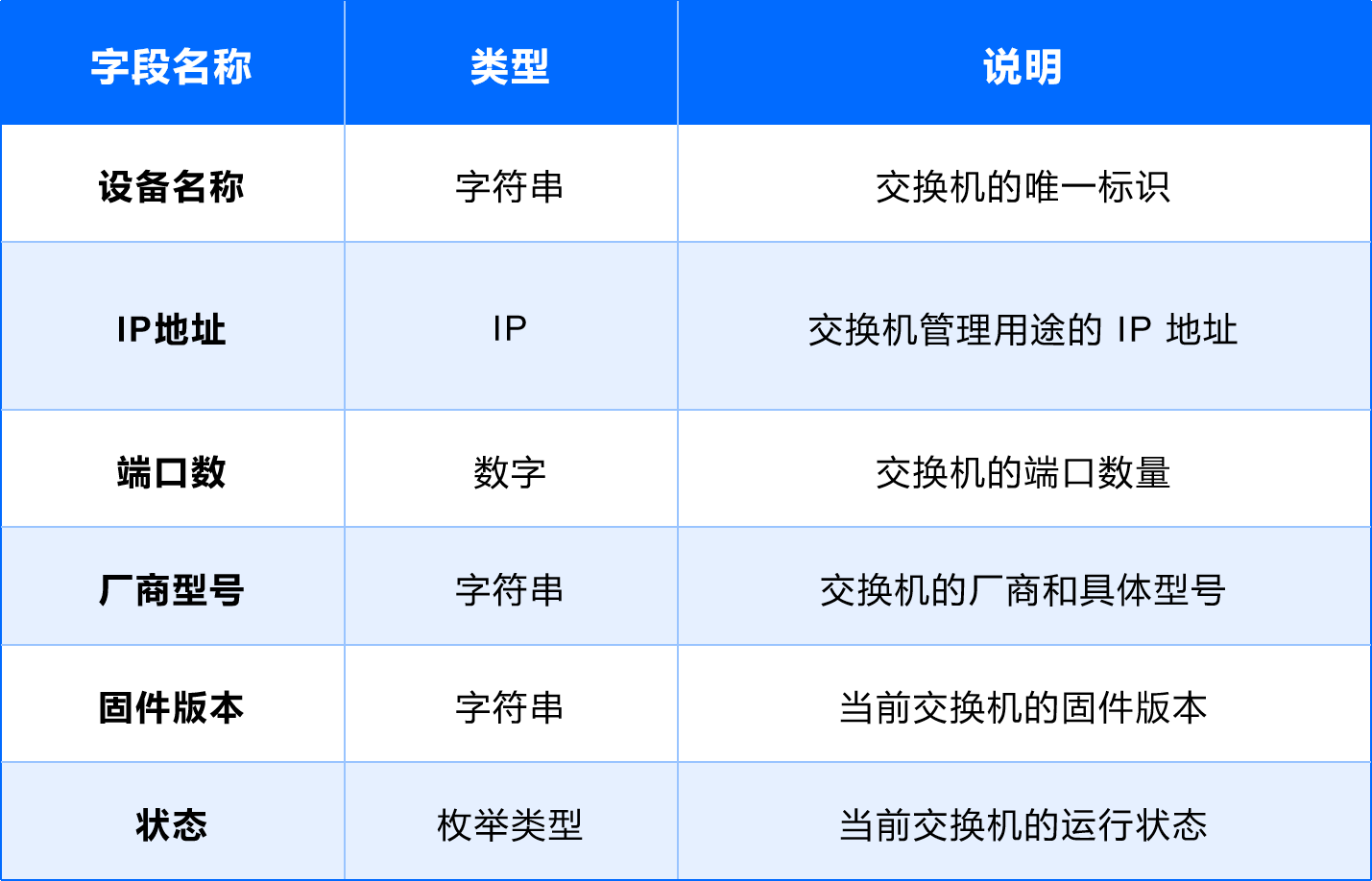
(7)路由器
用途:提供网络路由和路径选择。
字段设计:
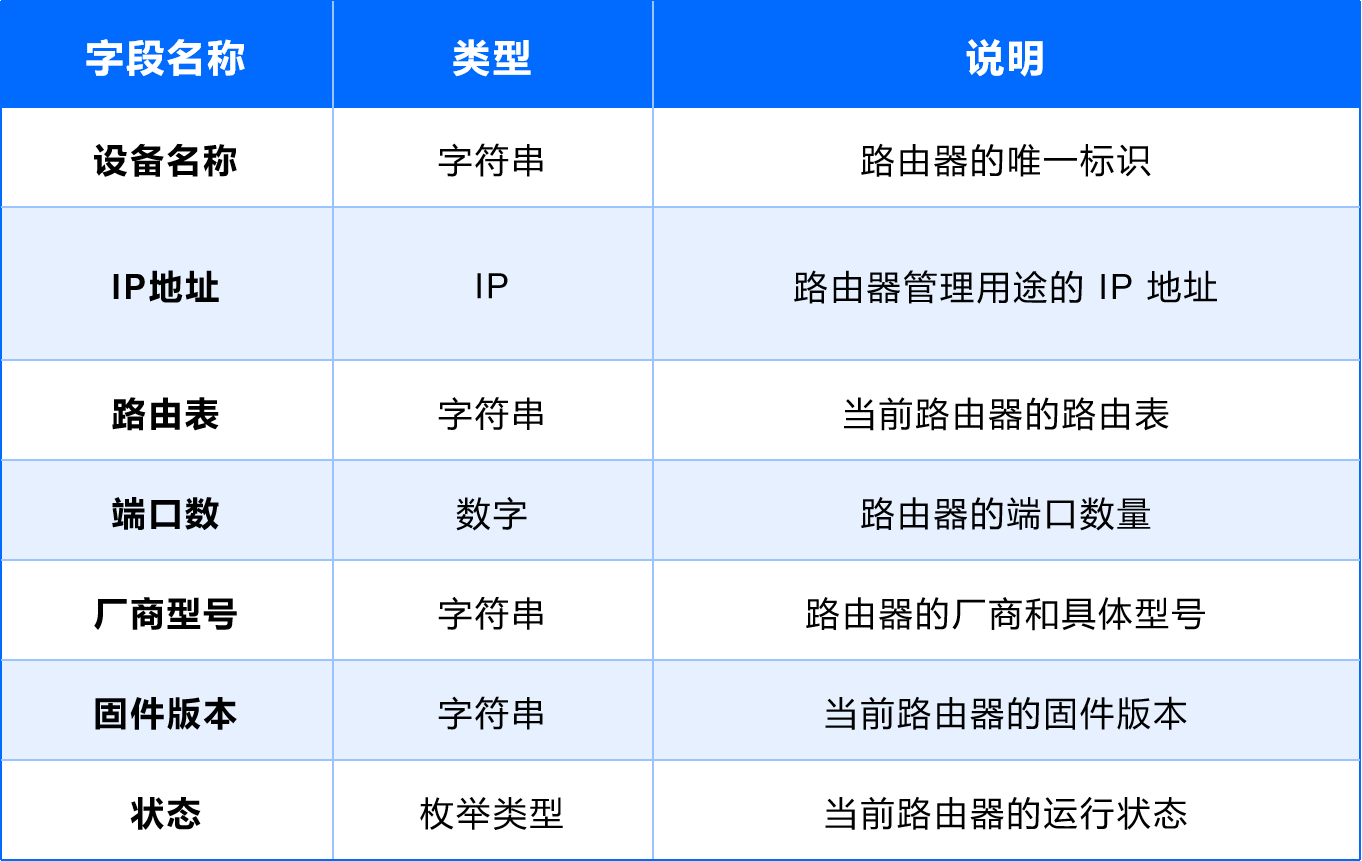
CI 模型的建立是 CMDB 拓扑建设的基础步骤。在设计 CI 的过程中,需始终遵循最小化原则,确保字段设计精简而高效,同时兼顾实际运维需求。通过针对不同场景设计的 CI 模板,我们能够实现 IT 环境的结构化管理,为下一步的 CI 关系设计和全链路故障排查奠定良好基础。
在下一章中,我们将继续深入,讲解如何基于这些 CI 模型建立起资源之间的关系,以形成真正的全链路拓扑图。
04.CI 关系的建立
CI 的属性定义能够帮助我们清晰地描述每一项 IT 资源,但仅仅依靠单一的 CI 信息是不足以支持复杂 IT 系统的故障定位。全链路故障排查的核心,是依赖于各个 CI 之间的关系建模。通过精准定义和捕获这些关系,我们可以构建一张全面的故障排查拓扑图,实现从业务到底层设备的全链路可视化。
在本章中,我们将介绍 CI 之间关系在拓扑中的重要性、关系类型的分类与设计原则,并提供一系列典型的关系建模示例。
1)关系在拓扑中的重要性
每个 IT 系统的资源和组件,并不是孤立运行的,几乎所有的资源都依赖于彼此共同协作。如果拓扑结构缺乏准确的关系建模,就可能导致以下风险:
- 故障定位模糊:某个应用故障背后可能有多种原因,例如网络中断、主机宕机或存储异常。如果关系不明晰,可能会导致故障排查耗费大量时间。
- 维护复杂度增加:当系统规模扩展时,不了解资源间的依赖关系会导致部署和变更风险剧增。
基于这些问题,定义 CI 关系是构建 CMDB 拓扑的关键环节。通过合理的关系建模,我们可以:
- 快速明确“谁依赖谁”;
- 构建资源间的调用与传递链路;
- 识别不同子系统之间的潜在影响。
2)关系类型的设计
CMDB 的 CI 关系可以通过多种方式定义,在故障排查的场景下,建议划分为以下几种通用类型:
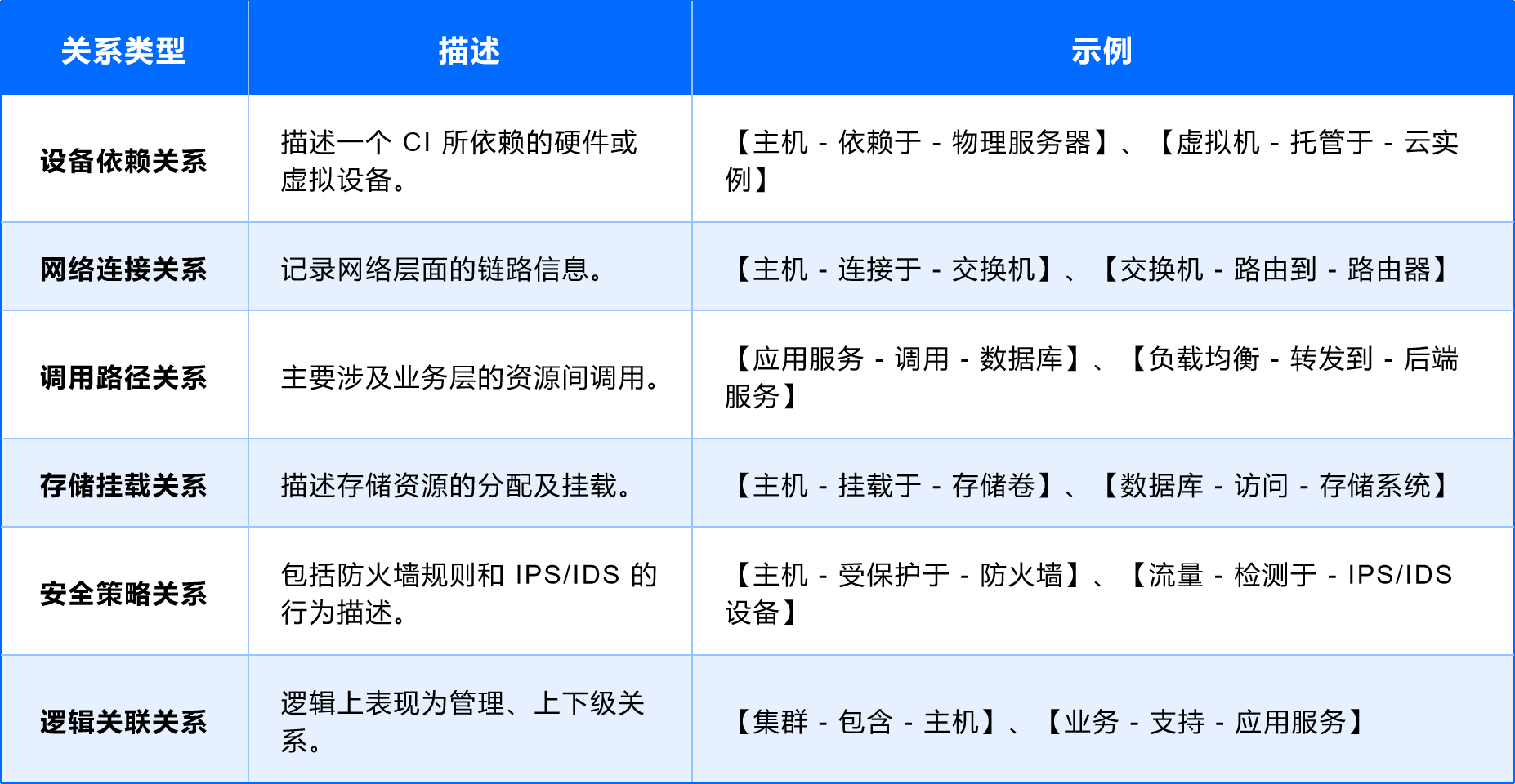
3)典型关系建模示例
以下是针对用户常见场景的关系建模示例,更直观地说明各种关键关系的设计。
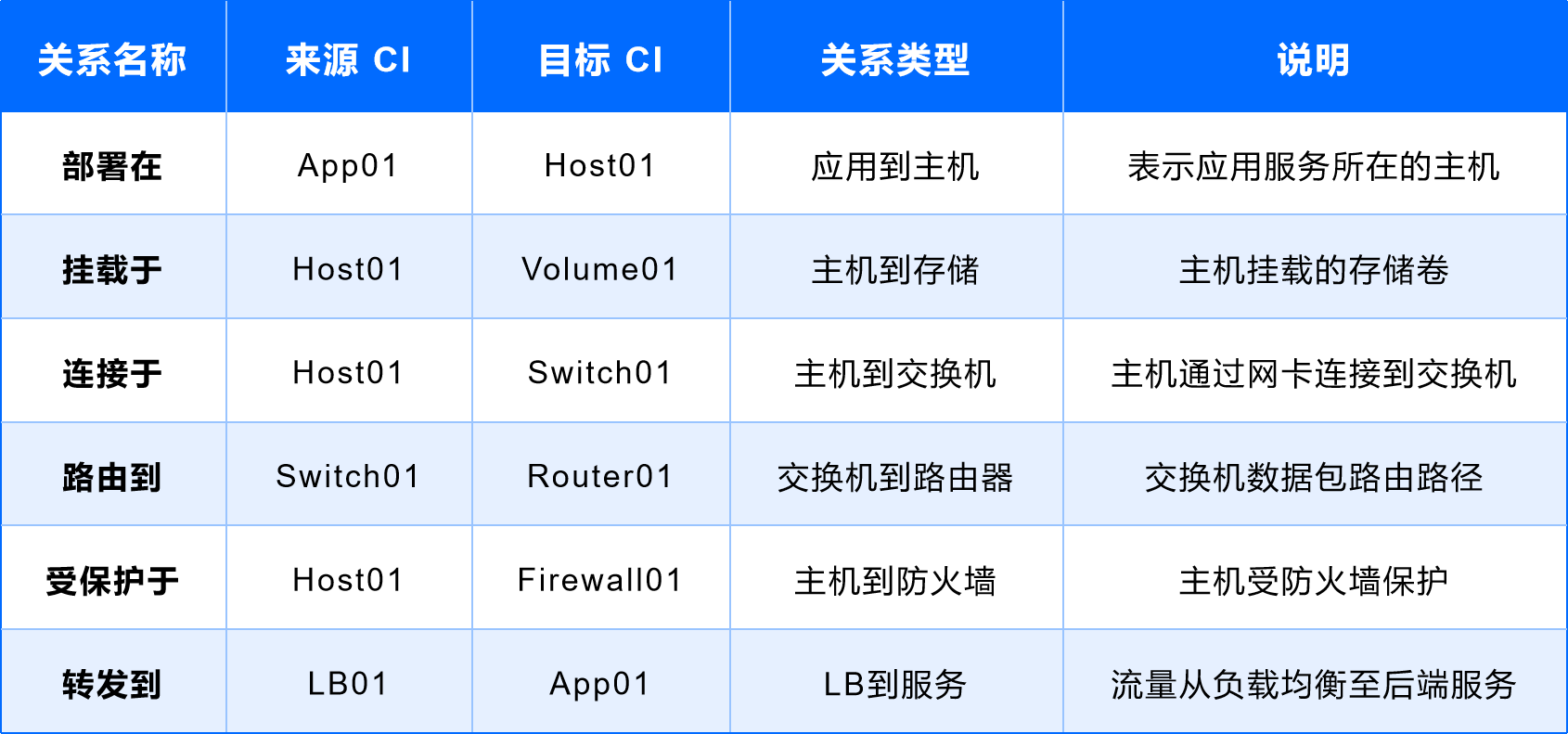
(1)应用服务与主机
- 关系类型:应用服务 - 部署在 - 主机
- 示例解读:如某业务应用 App01 部署在主机 Host01 上,则通过这段关系,可以快速定位支撑应用运行的主机资源。
- 逻辑关系:App01 (来源 CI) 部署在 Host01 (目标 CI)
- 关系类型:主机 - 连接于 - 交换机
- 示例解读:主机 Host01 通过网卡绑定到交换机 Switch01 的某一端口,可用于定位网络链路故障。
- 逻辑关系:Host01 (来源 CI) 连接于 Switch01 (目标 CI)
- 关系类型:主机 - 挂载于 - 存储卷
- 示例解读:主机 Host01 与存储卷 Volume01 之间建立了一组挂载关系。通过此关系可以快速定位存储性能问题带来的影响。
- 逻辑关系:Host01 (来源 CI) 挂载于 Volume01 (目标 CI)
- 关系类型:交换机 - 路由到 - 路由器
- 示例解读:交换机 Switch01 将流量路径路由到路由器 Router01,从而完成网络通路的建立。
- 逻辑关系:Switch01 (来源 CI) 路由到 Router01 (目标 CI)
- 关系类型:业务或主机流量 - 检测于 - 防火墙
- 示例解读:业务流量通过防火墙 Firewall01 进行过滤,涉及访问控制和安全策略。
- 逻辑关系:APP01、Host01 (来源 CI) 检测于 Firewall01 (目标 CI)
- 关系类型:负载均衡 - 转发到 - 应用服务
- 示例解读:负载均衡设备 LB01 负责将外部流量分发到后端应用 App01。
- 逻辑关系:LB01 (来源 CI) 转发到 App01 (目标 CI)
CI 关系的建立是 CMDB 中实现全链路管理的核心环节。关系的类型需要根据具体场景和运维目标进行划分,以确保“谁依赖谁”“谁影响谁”清晰明了。通过合理设计关系模型和实现动态更新能力,我们可以构建一个结构清晰、实时准确的故障排查拓扑,为解决复杂故障提供支持。
接下来,我们将继续讨论如何通过工具和技术手段采集这些关系及其属性,使拓扑建设更高效、更动态地反映实际状态。
05.CI 属性和关系的采集
创建了 CI 模型和关系模型之后,接下来的重要任务是如何准确、高效地采集这些 CI 的属性和关系。采集数据不仅要保证准确性,还需要覆盖全链路的实时动态变化,以确保 CMDB 中的数据始终与实际状态保持一致。
1)数据采集的核心原则
- 准确性:确保采集的数据真实可靠,这是 CMDB 的基础要求。错误或陈旧的数据将导致拓扑图失效,进而影响故障排查和系统管理。
- 动态性:IT 环境是动态变化的,采集数据必须能够及时反映资源和关系的变化,以保持与实际情况同步。
- 全面性:数据采集应覆盖所有关键的 CI 和关系,避免任何遗漏,做到全链路清晰可查。
- 安全性:采集过程中必须遵循企业的安全策略,避免数据泄漏和未授权访问。
2)CI 属性采集
CI 属性数据可以通过多种方式采集,以下是常用的几种方法:(1)Agent-based 采集
通过在主机或设备上部署采集 Agent 实时获取配置和状态数据。
- 工具示例:蓝鲸 Agent ,通过配置发现工具下发插件进行周期性采集。
- 优点:实时性高,能获取详细的指标和状态信息。
通过标准化协议(如 SNMP、SSH)或系统 API 获取数据,不需要在设备上安装采集工具。
- 工具示例:SNMP 采集工具、第三方 API 脚本,通过蓝鲸 Agent 在作业机上执行对应采集命令。
- 优点:不需要额外的 Agent 部署,降低入侵风险。
- 示例命令:
(3)日志和事件数据采集
通过采集系统日志和事件日志数据,获取 CI 的状态和变更情况。
- 工具示例:通过蓝鲸 Agent 进行日志采集,并用采集插件做日志清洗,结构化。
- 优点:可以集成丰富的日志分析能力,有助于故障根因分析。部分数据难以通过 API 获取的可以从日志里面提炼,是一个有力的补充数据源。
3)CI 关系的采集
相比于属性数据,关系数据的采集通常更为复杂,需要系统化的工具和方法。以下是几种常见的关系采集技术及其具体示例。(1)网络扫描与链路检测
通过自动化网络扫描工具,识别各网络设备之间的链路关系。
- 工具示例:Nmap、Netdisco。
- 优点:能全面扫描网络设备,自动识别链路关系。
- 示例命令:
nmap -sP 192.168.0.0/24
(2)API 数据采集
通过各系统提供的 API 接口,获取相关系统及服务间的调用和依赖关系。- 工具示例:curl、Postman、Python requests 库。
- 优点:能够直接调取系统数据,灵活可扩展。
- 示例命令:
http://application/api/resource/list
(3)主机 Agent 采集
通过在主机上部署采集 Agent,实时获取配置、依赖关系和运行状态数据,包括主机与其上部署的数据库、中间件的依赖关系。- 工具示例:蓝鲸 Agent ,通过配置发现工具下发插件进行周期性采集。
- 优点:实时性强:能够持续采集主机相关的运行时信息。依赖精确性:自动发现主机与数据库、中间件的依赖关系。可扩展性:可将采集到的数据发送到 CMDB 或监控系统用于后续分析。
(4)虚拟化/云平台命令采集
通过虚拟化平台(如 vCenter、Kubernetes)或云平台(如 AWS、Azure)的原生命令接口,获取虚拟资源与物理资源的关系数据。- 工具示例:govc(vCenter)、kubectl(Kubernetes)。
- 优点:能够全面管理和监控虚拟化和云环境中的资源。
- 示例命令:
govc vm.info -json -vm <vm-name>
# 使用 kubectl 获取 Kubernetes 节点信息
kubectl get nodes
(5)服务发现与链路追踪
用于微服务架构的服务发现与链路追踪系统,自动维护服务间的依赖关系和调用路径。- 工具示例:Consul 、APM 工具如鲸眼 APM 。
- 优点:专为微服务架构设计,自动化程度高。
- 示例命令:
consul agent -dev
4)关系采集案例
以下表格全面展示了不同类型关系的采集方法、使用工具、具体采集命令及命令执行位置,确保实现全链路拓扑的建立。
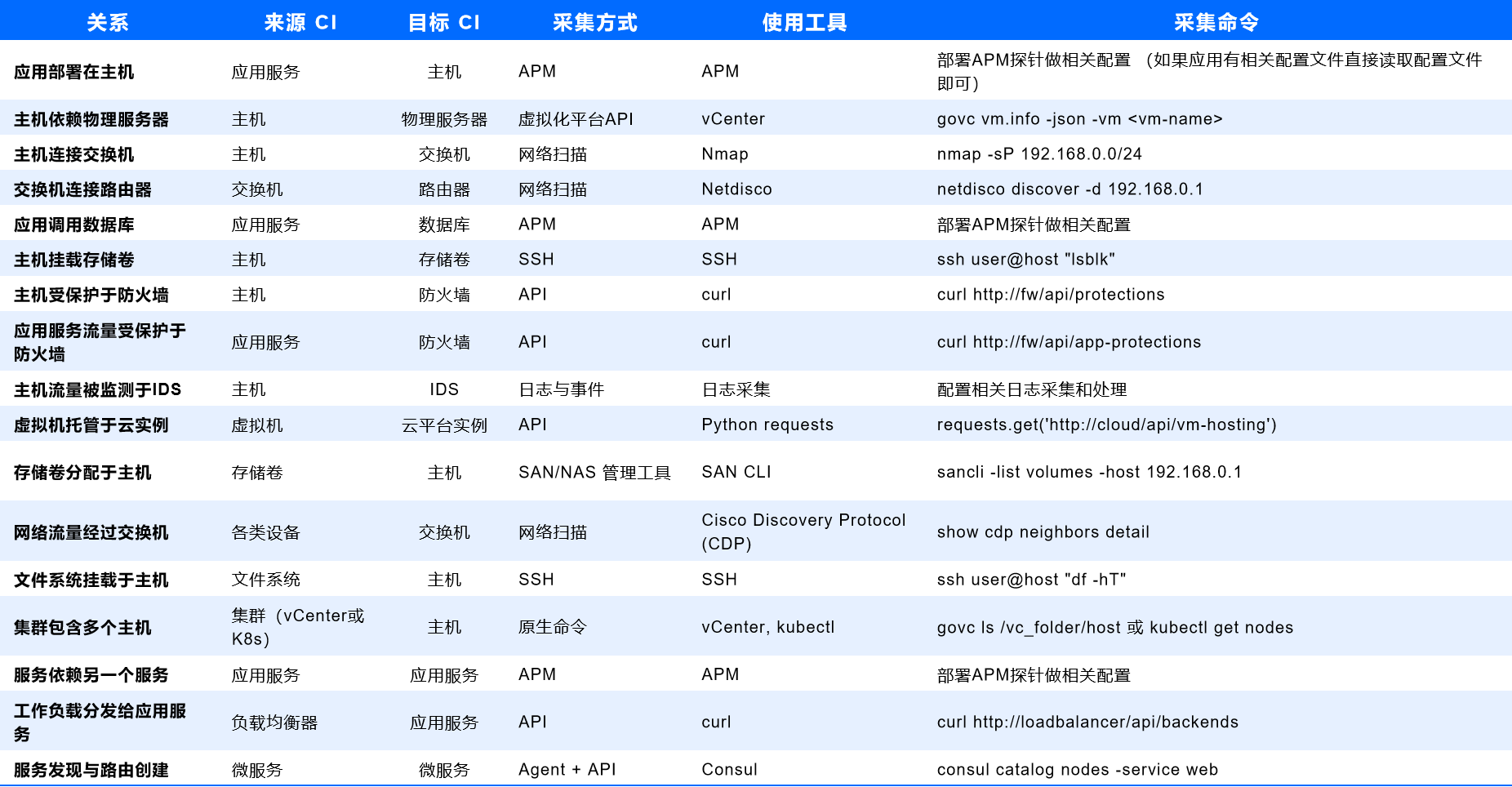
06.CMDB拓扑在故障排查中的应用示例
在这一章,我们将以具体案例演示如何充分利用 CMDB 全链路故障排查拓扑,在复杂的 IT 环境中快速定位故障根因并高效解决问题。这些示例涵盖了从应用层到物理层的各种常见故障场景。
1)示例一:应用服务不可用
故障描述:某一关键业务应用服务发生 502 错误,用户无法访问应用服务。
排查步骤:
(1)检查负载均衡状态:查看负载均衡设备的健康检查状态。
- 命令:curl http://lb/api/health-checks
- 如果负载均衡健康,则表示请求已成功发送到后端服务器
- 使用 CI 关系:应用服务 - 部署在 - 主机
- 确认实际运行状态。
- 命令:curl http://app/api/status
- 目标主机信息可以通过 CMDB 获得。
ssh user@host01
top # 查看实时系统资源使用情况
df -h # 检查磁盘使用情况
(4)检查询主机网络链路:确认主机与交换机之间的连接是否正常。
- 使用 Nmap 检查内部网络状态。
- 命令:
(5)检查应用调用路径:查看应用服务是否成功调用了后端数据库。
- 使用 CI 关系:应用服务 - 调用 - 数据库
- 命令:curl http://app/api/db-status
2)示例二:网络性能问题
故障描述:某业务网络流量中断或出现大量丢包。
排查步骤:
(1)通过 CMDB 确认该网络链路上的相关对象。
(2)确认主机与交换机的连接状态:检查主要业务主机的网络连接状况,确认是否存在断网或连接异常。
ssh user@host01
ifconfig # 查看网络配置及连接状态
ping 192.168.0.1 # 测试与交换机的连接
(3)检查交换机到路由器链路:使用 Cisco Discovery Protocol (CDP) 或 LLDP 工具检查交换机与路由器的连接健康状况。
ssh user@switch01
show cdp neighbors detail # 或 show lldp neighbors detail
(4)检测云平台的网络链路:如果主机托管于云平台,使用云平台 API 查询虚拟网络是否正常。
curl http://cloud/api/vm-network-status
(5)检查防火墙策略:查看防火墙是否在相关流量中施加了限制或有新的策略变动。
- 命令:curl http://firewall/api/policies
snmpwalk -v2c -c public 192.168.0.1
(7)最终确认:结合以上信息找出网络链路中的具体问题环节,是否交换机端口丢包、链路中断还是防火墙策略导致网络性能降低。
3)示例三:存储系统性能瓶颈
故障描述:某业务系统日志显示 IO 性能下降,导致应用响应时间变长。
排查步骤:
(1)确定受影响主机和应用:通过 CMDB 确认相关应用和主机。使用 CI 关系:应用服务 - 部署在 - 主机
(2)检查主机磁盘 IO 状况:登录受影响的主机,检查磁盘 IO 的具体情况。
ssh user@host01
iostat -x # 查看磁盘 IO 性能
(3)确认存储接口和路径:使用 CMDB 信息,查找主机挂载的存储卷。
- 使用 CI 关系:主机 - 挂载于 - 存储卷
- 命令:ssh user@host01 "lsblk"
ssh user@storage
sancli -list volumes -volume Volume01
(5)检查存储网络路径:确认存储路径上各节点(如交换机、SAN)是否存在性能瓶颈。汇总网络链路和存储链路的具体表现。
(6)最终确认:通过以上步骤,确定存储系统性能下降的具体原因,是由于主机 IO 高峰,SAN 网络瓶颈还是存储设备的问题。
通过这些具体的故障排查案例,我们展示了如何利用 CMDB 全链路故障排查拓扑,在复杂 IT 环境中快速、准确地定位故障,提升运维效率。接下来的章节将讨论 CMDB 的未来发展方向及其在智能运维中的广泛应用。
07.总结与展望
1)总结
通过本文的介绍,我们完整地展示了如何基于 CMDB 建立全链路故障排查拓扑。从拓扑建设的基本思路到实际关系建模,再到具体的采集技术和实际应用示例,主要涵盖以下几个方面:
(1)拓扑建设思路:
- 从以业务为中心的视角出发,梳理 IT 环境中关键资源的依赖关系。
- 结合自顶向下的逻辑规划和自底向上的数据采集方法,确保业务与底层设备的关联完整清晰。
- 基于最小化原则设计 CI 模型,保证字段简洁且实用。
- 模型覆盖了负载均衡器、应用服务、主机、存储系统、网络设备(如交换机、路由器、防火墙、IPS、IDS)等在内的 IT 核心设施。
- 定义并建立 CI 之间关键关系,包括部署、网络连接、业务依赖、存储挂载、安全防护等。
- 基于关系建模实现故障排查中的“谁依赖谁”“谁影响谁”的逻辑链条。
(5)实际应用示例 :通过实际的故障排查场景(如应用服务不可用、网络性能问题、存储系统性能瓶颈),展示了如何利用 CMDB 拓扑实现快速、精确的根因分析。
- 提供了对整个 IT 环境的全链可见性。
- 加快了问题根因分析速度。
- 支持了动态环境中的持续更新和拓扑展现。
2)CMDB的智能化未来发展
随着 IT 基础设施的持续演进,CMDB 面临的挑战也在逐步加大,尤其是在云原生、微服务和边缘计算环境中,传统的 CMDB 系统因数据更新缓慢、关系定义复杂等局限,难以准确支撑快速变化的 IT 环境。然而,随着大数据、人工智能(AI)的融合,CMDB 的潜在能力将被进一步释放。以下从数据采集治理和数据消费两个方向展开讨论。
(1)CMDB 数据采集治理
1. 动态化与实时更新能力
- 目标:解决传统 CMDB 数据更新缓慢、难以反映动态环境变化的问题。
- 解决方案:通过集成实时监控工具(如 Prometheus、Zabbix)和自动化采集工具(如 vCenter SDK、Kubernetes 原生接口),CMDB 可以自动感知资源上线、配置变更、状态异常等动态事件。
- 效果或示例:实现对资源变化的实时响应。确保 CMDB 数据的实时性与环境同步。
- 目标:减少人工配置资源关系的工作量,提高依赖关系发现的准确性。
- 解决方案:利用机器学习和数据挖掘技术,自动发现资源之间的隐藏依赖及潜在关系。例如,通过聚类算法分析日志数据和网络流量路径,或通过时间序列模型分析资源性能波动与故障模式。
- 效果或示例:自动更新资源拓扑,减少人工操作。动态优化资源依赖关系,提高运维效率。
- 目标:提高数据质量,确保 CMDB 数据准确、一致。
- 解决方案:利用大模型的自然语言处理能力,自动检测和清理 CMDB 数据中的错误和冗余。
- 效果或示例:清除重复数据、修复配置错误。
- 目标:识别并修正潜在的资源依赖关系,提高 CMDB 数据的纵深度。
- 解决方案:通过大模型分析历史数据和配置,自动补充或推测尚未显式定义的依赖关系。
- 效果或示例:推理潜在的跨区域网络依赖。
- 目标:解决云原生架构的弹性伸缩、动态调度和多云部署带来的数据采集复杂性问题。
- 解决方案:通过整合 Kubernetes API、OpenStack API 等云原生工具,实时更新云平台资源,并实现以下能力:快速发现业务 Pod 的运行节点并反映到 CMDB 。在多云场景下,统一展示资源跨平台的调用和依赖关系(如混合云环境中的主机与存储)。
- 效果或示例:消除云原生复杂性带来的数据孤岛问题,构建云平台资源的统一视图。
1. 与 AIOps 的深度集成
- 目标:通过结合大数据分析和智能算法,提升故障检测、影响评估和自动化响应的效率。
- 解决方案:AIOps 利用 CMDB 提供的全量配置数据和拓扑关系,进行智能化故障预测和根因分析。
- 效果或示例:提前预测资源瓶颈:如主机 CPU 长期高负载。智能根因定位:快速确定故障原因,并动态评估业务影响范围。
- 目标:提升拓扑图的可交互性和直观性,让运维人员更直观地理解资源关系,快速排查问题。
- 解决方案:动态生成可交互的拓扑图,支持多层级链路钻取和基于业务流的分析视图。
- 效果或示例:集成 3D 动态拓扑视图,结合 Grafana 等工具展示系统健康状况及变化趋势。提供拓扑模拟功能,支持 "What If" 场景分析,例如模拟某节点故障后的业务影响。
- 目标:提高交互效率,使运维人员以自然语言查询和获取 CMDB 数据。
- 解决方案:基于大模型构建自然语言接口,例如,“告诉我主机 Host01 上运行的所有应用服务。”
- 效果或示例:通过问答窗口用自然语言对话直接给出查询和统计结果。
- 目标:根据 CMDB 数据和运维场景提供个性化操作建议,提高运维效率和准确性。
- 解决方案:大模型基于当前数据给出扩容建议或优化策略。
- 效果或示例:根据主机 CPU 使用历史,推荐增加资源。
- 目标:提高问题解决的自动化程度,减少人工干预。
- 解决方案:大模型结合 CMDB 数据,生成故障处理方案。
- 效果或示例:从日志中发现异常信息,基于CI关联的工单解决方案自动生成恢复命令。
相关文章推荐
100+案例淬炼:应用投产变更管理最佳实践

 2026-02-09
2026-02-09
查看详细


嘉为蓝鲸DevOps|业务人员跨界修缺陷?AI 打通DevOps全链路,提效超乎想象!
2026-02-09
查看详细
【运维自动化规划】自动化作业设计:从原子操作到流程编排的工程化实践
2026-01-09
查看详细
嘉为蓝鲸DevOps研发测试一体化:从信息孤岛到双向穿透,构建高效协同新范式
2026-01-09
查看详细
嘉为蓝鲸DevOps缺陷管理协同中枢:破解 “单测多研” 质量困局,打造高效协同新范式
2025-12-26
查看详细
【运维自动化规划】自动化场景设计:从组件级到混合场景的全链路自动化构建
2025-12-26
查看详细







